
許多數字服務的設計不僅依賴於數據操作和信息設計,還依賴於用戶學習系統。

一般來講,數字服務的體驗遵循預定義的用戶旅程,具有明確的狀態和動作。 一直以來,設計師的工作一直是創建線性工作流,並將其轉化為可以理解和不引人注目的體驗。 但是這種情況可能會成為過去時。
過去6個月,我一直在BBVA Data&Analytics(D&A)任職一個相當獨特的職位,這是一家卓越的財務數據分析中心。 我的工作是利用新興的機器學習技術,使用戶體驗設計得到提昇平。
除此之外,我的職責是為數據科學團隊帶來整體的體驗設計,並使其成為算法解決方案的生命週期(例如預測模型、推薦系統)的重要組成部分。 同時,我會對設計團隊的體驗設計進行創造性和戰略性的優化(例如網上銀行、網上購物、智能決策),引導它們發展演變為“人工智能”的未來。
事實上,我通過促進設計師和數據科學團隊之間的交流合作,來達到設計出由數據和算法驅動的理想的和可行的用戶體驗的目的。
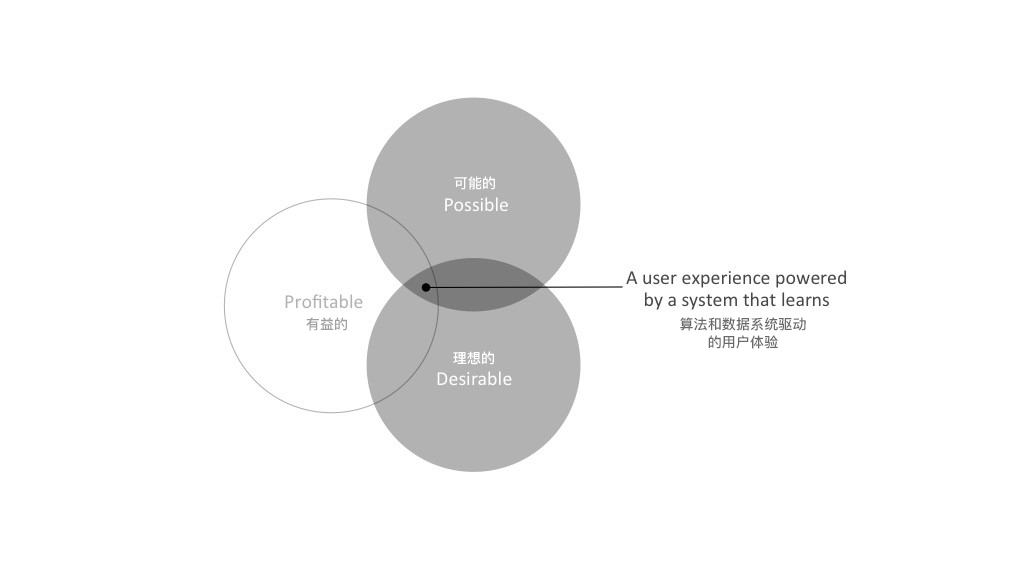
我們定義了一種不同的體驗設計,即人類行為學習系統用戶體驗。 這是一個新的嘗試,因為:
- 它創造了新的用戶體驗類型。
- 它重新定義了人與機器之間的關係。
- 它要求設計師和數據科學家之間緊密合作。
接下來將會具體闡述這些內容的含義。
新型用戶體驗
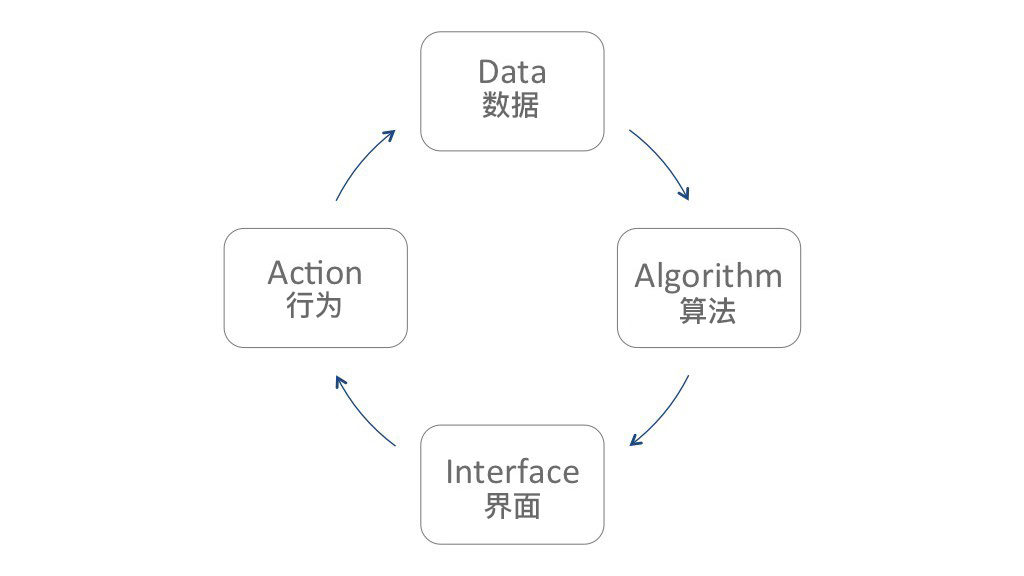
如今,許多數字服務的設計不僅依賴於數據操作和信息設計,還依賴於用戶學習系統。 如果深入剖析這些系統,我們會發現行為數據(例如人的交互,系統交互)被作為內容提供給生成知識的算法。 傳播知識的界面則使得體驗更加豐富。 理想情況下,這種體驗會尋求明確的用戶操作或後台關鍵事件數據來創建一個反饋循環,該循環將為算法提供學習材料。
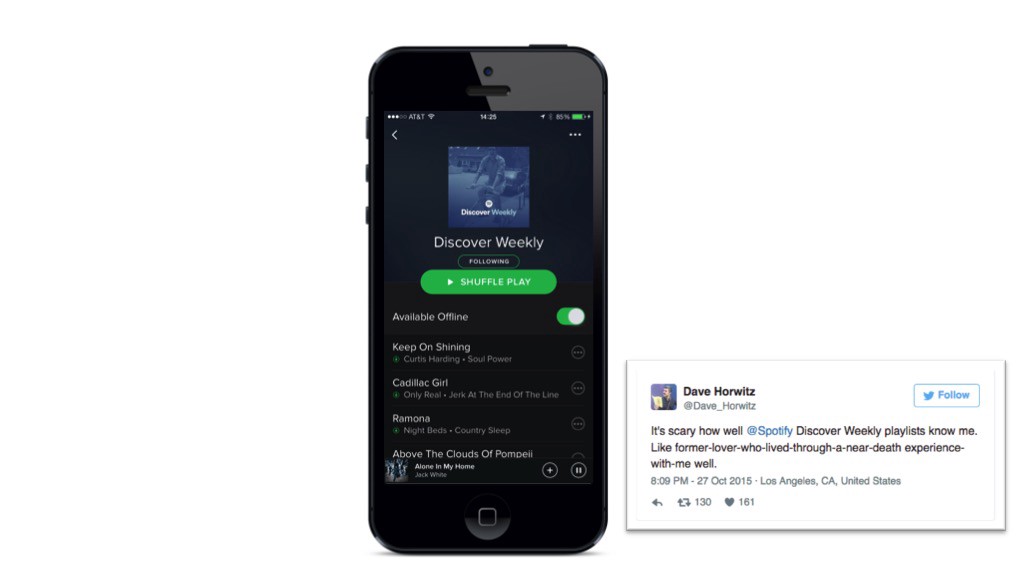
舉個實際的例子。 你知道Spotify “發現每週”是如何工作的嗎?
“發現每週”是Spotify的自動音樂推薦“數據引擎”,每星期專門為每個Spotify用戶量身定制兩小時的定制音樂推薦。
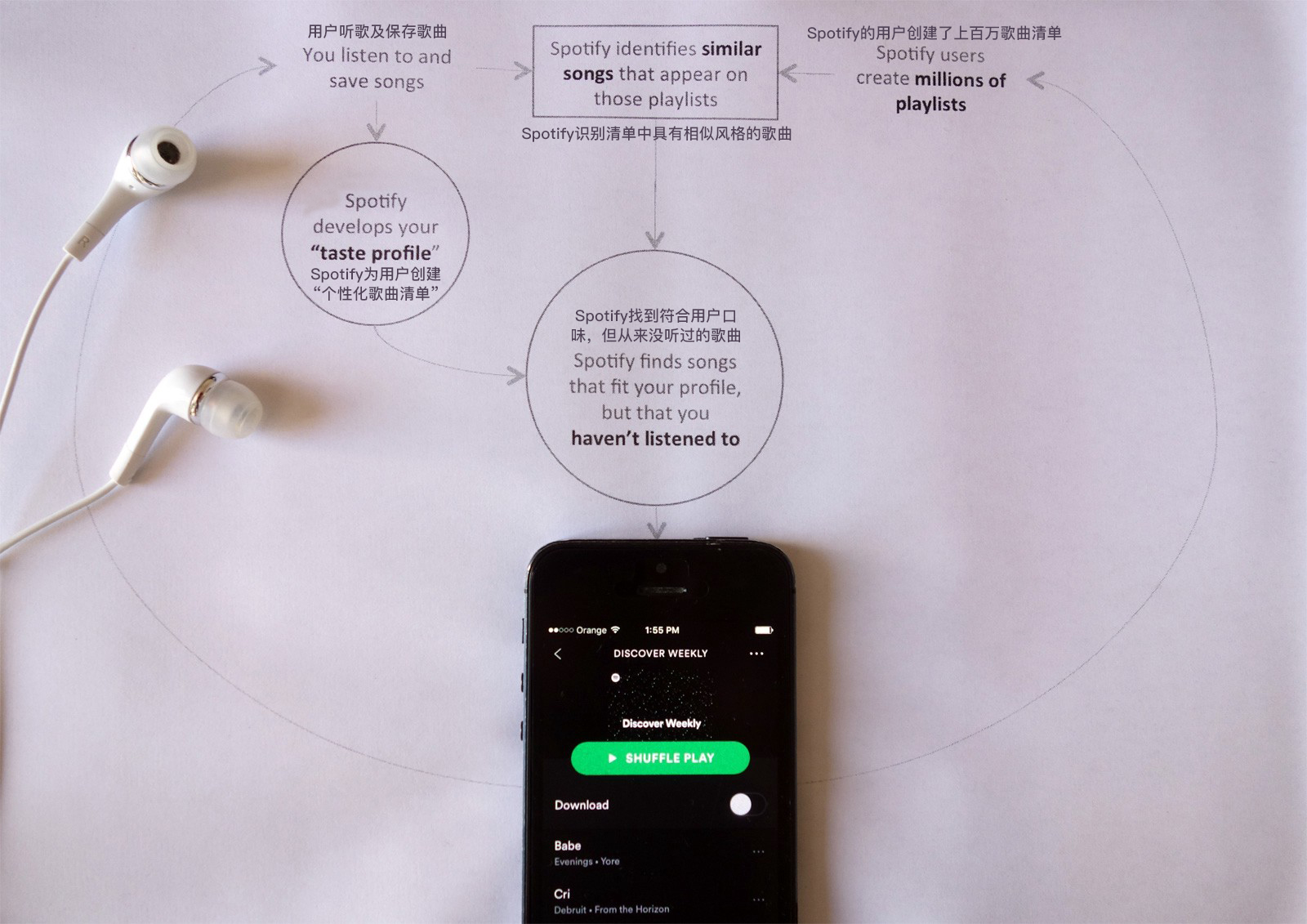
架構改編使得Spotify的“發現每週”的播放列表具有強大吸引力
“發現每週”的推薦系統利用Spotify用戶創建的數百萬個播放列表,為公司的專業播放列表和那些擁有廣大粉絲群的播放列錶帶來額外的權重。 該算法試圖強化那些具有相似品味的用戶的聽歌習慣。 它有三個主要任務:
- 一方面,Spotify為每個用戶創建了個性化音樂品味的簡介,將其劃分為藝術家和少數流派;
- 另一方面,Spotify使用上億級的播放列表,根據播放列表中歌曲的風格特點,去建立具有相似音樂風格的播放列表
- 每週它都會根據每個用戶的個人口味去創建推薦列表。 基本上,如果一首最喜歡的歌曲與一首未曾聽過的歌曲一起出現在播放列表中,那麼它就會推薦那首新歌。
一般來說,“發現周刊”播放列表會推薦30首歌曲,這個歌曲列表的內容已經足夠多了,可以較好地去發現與個人品味相匹配的音樂。 這樣做的好處是可以生成數千個新的播放列表,這些新的播放列表在一周後會反饋到算法中以產生新的推薦。
這種反饋循環機制通常可以使現有的體驗實現個性化、優化或自動化的目的。 同時,它們還會根據建議、預測或情景來創造機會去設計新的體驗。 在D&A,我首次提出了一套不太全面的設計方法。
以下是其具體步驟:
為探索而設計
如你所見,推薦系統可以幫助發現已知的未知甚至未知的未知。 例如,Spotify通過對用戶聽音樂的行為與數十萬其他用戶的聽音樂行為之間的匹配來定義個性化體驗,從而幫助發現音樂。 這種體驗至少面臨三個主要的設計挑戰。
首先,推薦系統傾向於創建一個“過濾器”,將建議(如產品、餐廳、新聞項目、人員連接)限制在一個與過往行為緊密聯繫的世界。 為了避免這種問題,數據學家有時必須調整一些不太準確的算法,並增加一些隨機性的建議。
其次,讓用戶可以自主選擇推薦的各個部分也是一個很好的設計實踐。 例如,亞馬遜允許用戶刪除可能對建議產生不利影響的項目。 想像一下,顧客為他人購買禮物,這些禮物不一定是未來個性化推薦的數據參考。
最後,像Spotify這樣,依靠主觀推薦的系統可以使用戶對被推薦的內容擁有更多的主觀性和多樣性的選擇。 這種人為清理數據集或減小機器學習算法局限性的方法通常被稱為“人類計算”或“交互式機器學習”或“相關反饋”。
為決策而設計
數據和算法也提供了個性化決策的手段。 例如在D&A,我們開發了一套優秀的算法為BBVA客戶提供財務建議。
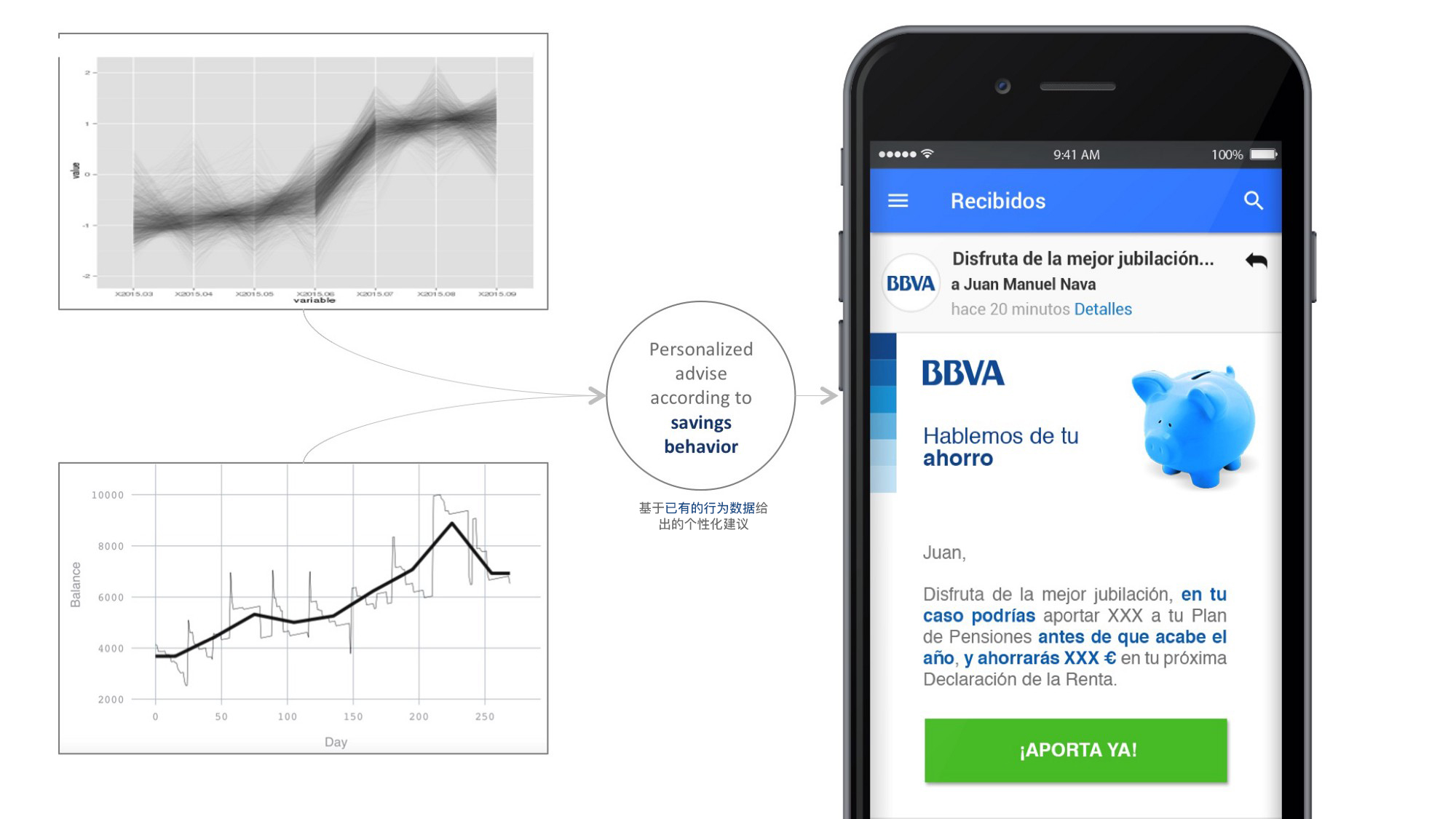
例如,我們根據賬戶餘額的時間演變來劃分儲蓄行為。 通過這種技術,我們可以根據每個客戶節省資金的能力來設計個性化投資機會。
這種決策性的算法對準確度有更高的要求,因為它們往往依賴於只能提供真實情況的數據集。 在財務諮詢的案例中,客戶可以在不同銀行操作多個賬戶,從而避免對儲蓄行為的洩漏。 目前來看這是一個比較好的設計實踐,因為它可以讓用戶隱晦或明確地提供不良信息。 數據學家的責任是明確反饋類型,從而豐富他們的模型,而設計師的工作是找到構成體驗組成部分的方法。
為不確定性而設計
傳統上講,計算機程序的設計遵循的是二進制的邏輯,即通過將具有明確的、有限集合的、具體的和可預測的狀態轉換成工作流程來實現 。 機器學習算法使用一種模糊邏輯來改變這種情況。 它們的目的是尋找一組大概率接近樣本行為規則的模式(參見Patrick Hebron的《為設計者的機器學習》一文中關於此定義的更加具體的介紹)。 這種方法包含一定程度的不精確和不可預知的行為。 它們經常會反饋一些關於已有信息精確度的提示。

例如,預訂平台Kayak通過分析歷史價格變化來預測價格的演變。 它的“預測”算法旨在讓用戶對是否在一個合適的時間購買一張票產生信心(參見Neal Lathia 《在票價背後的機器學習》)。 數據學家自然傾向於給出算法預測值的精確度:“我們預測這個票價是x”。 這個“預測”實際上是一個基於歷史趨勢的結果呈現。 然而,預測與告知並不相同,設計師必須考慮這樣的預測能夠支撐用戶的行為:“買!這個票價可能會增加”。 “可能”與“價格走勢的預測”是用戶體驗中的“完美銜接”,這個概念是由Mark Weiser在施樂帕洛阿爾托研究中心工作期間首次提出,然後由 Chalmers and MacColl進一步將其發展為一個 新的概念——seamful design(有縫設計):
“Seamful design故意向用戶展示“接縫”,並利用通常被認為是消極或有問題的特徵”。
Seamful design 利用失敗和局限來改善體驗。 它通過收集用戶對於不良設計細節的建議來改善系統。 DJ Patil描述了 Data Jujitsu 中的巧妙設計。
其他類型的機器學習算法運用精確度和召回率來處理接縫。
- 精確度評分體現了提供完全符合需求的結果的能力。 (精確度指的是算法推送的內容與用戶喜好的匹配程度)
- 召回率評分體現了提供大量可能的好建議的能力。 (召回率指的是算法推送的內容與用戶喜好匹配的內容的佔比)
算法的理想之處在於提供高精確度和高召回率。 不幸的是,精確度和召回率往往相互矛盾。 在許多數據分析系統中,設計決策經常需要在精度與召回率之間進行折中選擇。 例如,在Spotify 的發現周刊中,必鬚根據推薦系統的性能來決定播放列表的大小。 提供30首歌曲推薦的大播放列表可以凸顯Spotify的信心,足夠多的推薦歌曲增加了用戶獲取完美推薦的機率。
為參與而設計
今天,我們在網上閱讀信息是基於自身行為和其他用戶的行為產生的。 算法通常會評估社交和新聞內容的相關性。 這些算法的目的是通過推送內容獲取更高的參與度或通過發送通知來建立用戶閱讀習慣。 顯然這些為我們所採取的行動並不一定是從我們自身利益出發。

在註意力經濟中,設計師和數據學家都應該從用戶的焦慮、強迫、恐懼、壓力和其他精神負擔中學習。 資料來源:《地球村及其不適》。 照片來源:Nicolas Nova
可以說,我們進入了注意力經濟時代,主要的在線服務正在努力吸引人們,盡可能長時間吸引他們的注意力。 他們的業務是讓用戶在其平台上盡可能長時間的頻繁操作。 但是這也帶來了差的體驗,這些體驗經常伴隨著諸如懼怕錯過信息(FoMO)或 其他 困擾情緒,以此來麻痺用戶的參與。
注意力經濟的“演員”也使用麻痺用戶的方法,例如根據使用時長給予獎勵。 這與老虎機中使用的機製完全相同。 由此產生的體驗會促使服務(賭場)吸引用戶不斷地尋找下一個獎勵。 我們的手機已經成為通知、警告、消息、轉發、喜歡的“老虎機”,有些用戶每天平均檢查150次,或者更多。 今天,設計師可以使用數據和算法來挖掘人們日常生活中的認知漏洞。 這種新的能力對機器學習時代的設計原則提出了新要求(參見Aaron Weyenberg 的《優良設計的道德規範:連接時代的倫理原則)。
然而,用機器學習算法設計的體驗並不一定會成為一種“賭場”體驗。
為時間高效利用而設計
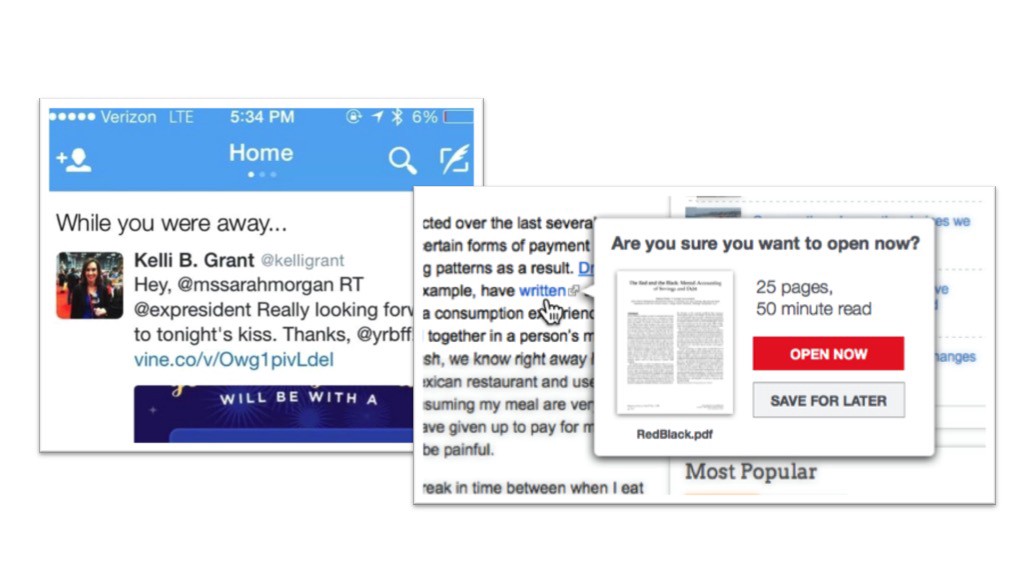
設計一個與眾不同的而不是約定俗成的體驗有很多方式。 事實上,像銀行這樣的組織有一定的優勢:它是一個以數據為基礎的行業,且不需要客戶花費大量的時間在他們的服務上。 Tristan Harris的“時間高效利用運動”在這個層面上具有重要意義。 他提倡使用數據緊密相關或完全不相關的體驗類型。 這種技術可以保護用戶注意力和尊重人們的時間。 twitter的“當你離開時……”是這種做法的一個很有說服力的案例。 其它服務則善於提示與其互動的時間。 這種體驗不是關注用戶留存量,而是關注交互的相關程度。
為內心平和而設計
數據學家擅長檢測正常行為和異常情況。 在D&A,我們正在努力促進BBVA客戶內心平和,這種機制在情況良好的情況下能夠提供一種通用意識,並觸發更多關於異常情況的詳細反饋。
我們認為目前這一代機器學習給社會帶來了新的力量,同時也增加了創造者的責任。 算法存在偏差並且可能是數據源固有的特徵。 因此,尤其需要注意使算法對於人們來說更清楚易懂,並且監管者可以對其進行審查,以了解其影響。 實際上,這意味著算法產生的內容應該保護用戶的興趣,並且應該解釋其評估的結果和使用的標準。
體驗設計其他相關的方面如下:
- 為公平而設計
- 為溝通而設計
- 為自動化而設計
可能還有更多方面的內容,期待更多人去發掘。
原文鏈接:https://medium.com/@girardin/experience-design-in-the-machine-learning-era-e16c87f4f2e2
本文由@百度UXC翻譯發佈於人人都是產品經理,未經許可,禁止轉載。
題圖來自PEXELS,基於CC0協議