
月活用戶越高的互聯網產品,被黑產盯上的可能性就越大。 在微信的安全生態裡,正是有網絡黑產的層出不窮,變化多端,才有了微信安全的不斷進化。 本文將帶你一窺究竟,微信是怎麼做異常檢測框架的?

如何在大規模數據下檢測異常用戶一直是學術界和工業界研究的重點,而在微信安全的實際生態中:
- 一方面,黑產作惡手段多變,為了捕捉黑產多變的惡意模式,若採用有監督的方法模型可能需要頻繁更新,維護成本較高;
- 另一方面,通過對惡意帳號進行分析,我們發現惡意用戶往往呈現一定的“聚集性”特徵,因此這裡需要更多地依賴無監督或半監督的手段對惡意用戶進行檢測。
然而,微信每日活躍帳號數基本在億級別,如何在有限的計算資源下從億級別帳號中找出可疑帳號給聚類方案的設計帶來了不小的挑戰,而本文則是為了解決這 一問題的一個小小的嘗試。
異常檢測框架設計目標及核心思路
設計目標為了滿足在實際場景檢測異常用戶的要求,在設計初期,我們提出如下設計目標:
- 主要用於檢測惡意帳號可能存在的環境聚集和屬性聚集;
- 方案需要易於融合現有畫像信息等其他輔助信息;
- 方案需要具有較強的可擴展性,可直接用於億級別用戶基數下的異常檢測。
核心思路通常基於聚類的異常用戶檢測思路是根據用戶特徵計算節點之間的相似度,並基於節點間相似度構建節點相似度連接圖,接著在得到的圖上做聚類,以發現惡意群體 。
然而,簡單的分析就會發現上述方案在實際應用場景下並不現實,若要對億級別用戶兩兩間計算相似度,其時間複雜度和空間消耗基本上是不可接受的。
為了解決這一問題,可將整個用戶空間劃分為若干子空間,子空間內用戶相似度較高,而子空間之間用戶之間的相似度則較低,這樣我們就只需要在每個用戶 子空間上計算節點相似度,避免相似度較低的節點對之間的相似度計算(這些邊對最終聚類結果影響較低),這樣就能大大地降低計算所需的時間和空間開銷。
基於這一想法,同時考慮到惡意用戶自然形成的環境聚集和屬性聚集,我們可以根據環境以及用戶屬性對整個用戶空間進行劃分,只在這些子空間上計算節點之間的相似度,並基於得到 的用戶相似度圖挖掘惡意用戶群體。
此外,直觀上來分析,如果兩個用戶聚集的維度越“可疑”,則該維度對惡意聚集的貢獻度應該越高,例如,如果兩個用戶同在一個“可疑”的IP 下,相比一個 正常的IP 而言,他們之間存在惡意聚集的可能性更高。 基於這一直覺,為了在每個用戶子空間內計算用戶對之間的相似度,可根據用戶聚集維度的可疑度給每個維度賦予不同的權值,使用所有聚集維度的權值的加權和 作為用戶間的相似度度量。
注:依據上述思路,需要在屬性劃分後的子空間計算兩兩用戶之間的相似度,然而實際數據中特定屬性值下的子空間會非常大,出於計算時間和空間開銷的考慮,實際 實現上我們會將特別大的group 按照一定大小(如5000)進行拆分,在拆分後的子空間計算節點相似度。 (實際實驗結果表明這種近似並不會對結果造成較大影響)
異常檢測框架設計方案
基於上述思路,異常檢測方案需要解決如下幾個問題:
- 如何根據用戶特徵 / 使用怎樣的特徵將整個用戶空間劃分為若干子空間?
- 如何衡量用戶特徵是否“可疑”?
- 如何根據構建得到的用戶相似度關係圖找出異常用戶群體?
為了解決以上三個問題,經過多輪的實驗和迭代,我們形成了一個較為通用的異常檢測方案,具體異常檢測方案框架圖如圖 1 所示:
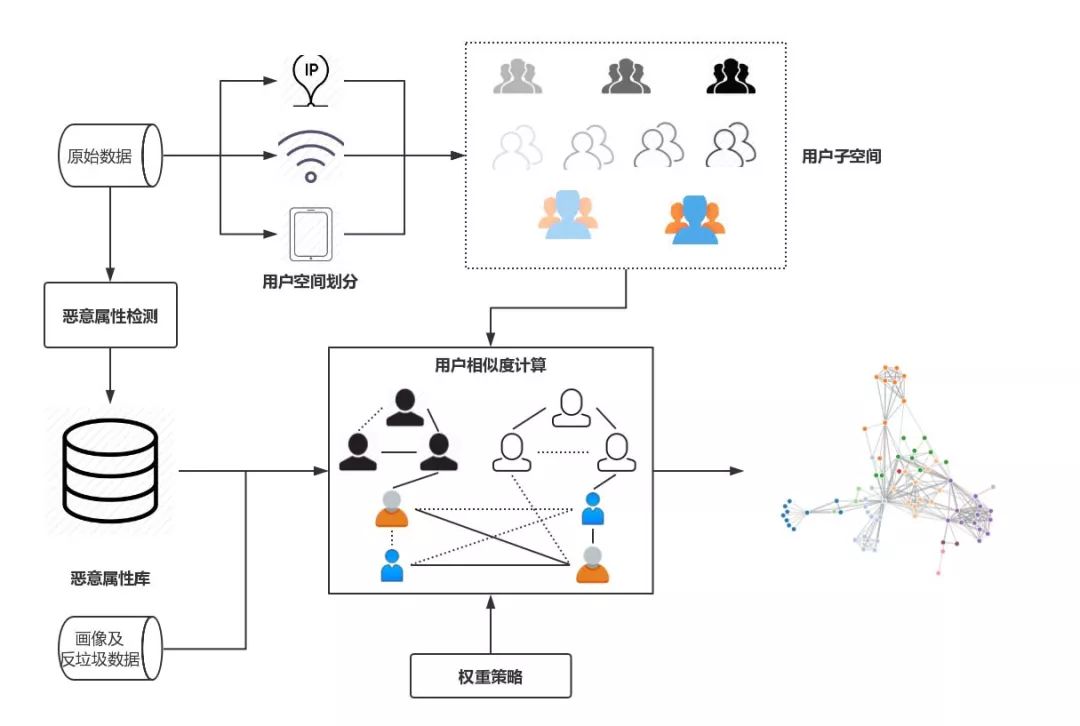
圖 1 異常用戶檢測框架
如圖1 所示,首先,用戶空間劃分模塊根據“劃分屬性”將整個用戶空間劃分為若干子空間,後續節點間相似度的計算均在這些子空間內部進行;惡意屬性檢測模塊則根據輸入數據 自動自適應地識別用戶特徵中的“可疑”值;用戶空間劃分和惡意屬性檢測完成後,在每個用戶子空間上,用戶相似度計算模塊基於惡意屬性檢測得到的惡意屬性庫和相應的權重 策略計算用戶之間兩兩之間的相似度,對於每個特徵以及其對應的不同的可疑程度,權重策略模塊會為其分配相應的權重值,用戶間邊的權重即為節點所有聚集項權重 的加權和,為了避免建邊可能帶來的巨大空間開銷,方案僅會保留權值大於一定閾值的邊;得到上一步構建得到的用戶相似度關係圖後,可使用常用的圖聚類算法進行 聚類,得到可疑的惡意用戶群體。
用戶空間劃分
為了進行節點間相似度的計算,首先需要將整個用戶空間劃分到不同的子空間中去,那麼這些用於劃分的屬性該如何選取呢? 經過一系列的實驗和分析,我們將用戶特徵劃分為以下兩類:
- 核心特徵:核心特徵指黑產帳號若要避免聚集,需要付出較大的成本的特徵,主要包括一些環境特徵;
- 支撐特徵:支撐特徵指黑產帳號若要避免聚集,改變所需成本較小的特徵。
不難發現,對於上述核心特徵,黑產規避的成本較大,所以在具體的劃分屬性的選取上,我們使用核心特徵對用戶空間進行劃分,並在劃分得到的子空間上計算節點對之間 的相似度。 在子空間上計算節點之間的相似度時,我們引入支撐特徵進行補充,使用核心特徵和支撐特徵同時計算用戶之間的相似度,以提高惡意判斷的準確率和覆蓋率。
何為“可疑”
可疑屬性提取
在確定劃分屬性後,一個更為重要的問題是如何確定哪些用戶屬性值是可疑的? 這裡我們主要對用戶脫敏後的登錄環境信息進行分析,依賴微信安全中心積累多年的環境畫像數據,通過對用戶屬性值的出現頻次、分佈等維度進行分析,提取出一些可疑的屬性值。
多粒度的可疑屬性識別
在進行養號識別的實驗過程中,我們發現,單純依靠若干天登錄數據的局部信息進行養號檢測往往無法達到較高的覆蓋率。 為了解決這一問題,在可疑屬性提取過程中,我們會融合安全中心現有的環境畫像信息以及反垃圾數據等全局信息輔助進行判斷,局部信息和全局信息的融合有以下兩個好處:
- 融合局部信息和全局信息,可增大可疑屬性判斷的置信度和覆蓋度,提高算法覆蓋率;
- 增加了用戶相似度計算設計上的靈活度,如若特定帳號與已封號帳號有邊相連,可通過賦予該邊額外的權重來加大對已知惡意用戶同環境帳號的打擊。
惡意用戶識別 

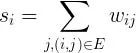

![]()
我們將超過一定閾值的用戶視為惡意用戶,其中,閾值可根據不同閾值得到的算法的準確率和覆蓋率選取一個合適的閾值。
另,處於性能和可擴展考慮,我們使用Connected Components 算法來識別可疑的用戶團體,同時,得到惡意團體後我們會對團體進行分析,提取在團體維度存在聚集性的屬性值,以增強模型的可 解釋性。
從百萬到億——異常檢測框架性能優化之路
初步實驗時,我們隨機抽取了百萬左右的用戶進行實驗,為了將所提方案擴展到全量億級別用戶上,挖掘可疑的用戶群體,我們做瞭如下優化:
Spark 性能優化
在基於 Spark 框架實現上述異常檢測框架的過程中,我們也碰到了 Spark 大數據處理中常見的問題 —— 數據傾斜。 分析上述異常檢測方案不難發現,方案實現中會涉及大量的groupByKey,aggregateByKey,reduceByKey 等聚合操作,為了規避聚合操作中數據傾斜對Spark 性能的影響,實際實現中我們主要引入了以下兩個策略: 兩階段聚合和三階段自適應聚合。
兩階段聚合
如圖 3 所示,兩階段聚合將聚合操作分為兩個階段:局部聚合和全局聚合。 第一次是局部聚合,先給每個key 都打上一個隨機數,比如10 以內的隨機數,此時原先一樣的key 就變成不一樣的了,比如(hello, 1) (hello, 1) (hello, 1) (hello, 1) 就會變成(1_hello, 1) (1_hello, 1) (2_hello, 1) (2_hello, 1)。 接著對打上隨機數後的數據,執行 reduceByKey 等聚合操作,進行局部聚合,得到局部聚合結果 (1_hello, 2) (2_hello, 2)。 然後將各個 key 的前綴給去掉,得到 (hello,2),(hello,2),再次進行全局聚合操作,即可得到最終結果 (hello, 4)。
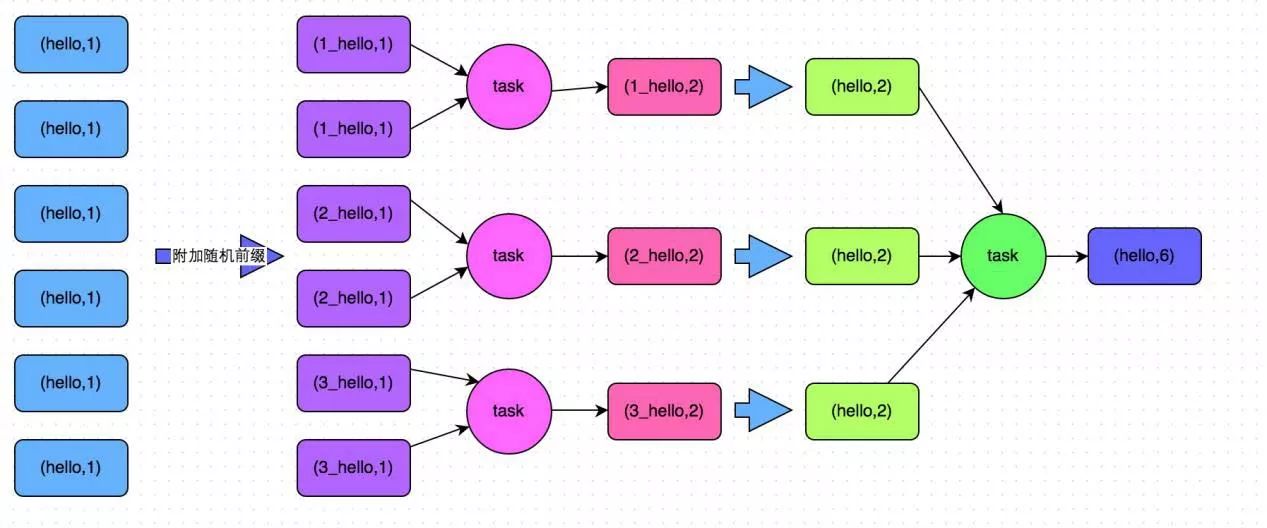
圖 3 兩階段聚合
三階段自適應聚合
用戶空間劃分階段我們需要將整個用戶空間根據劃分屬性劃分為若干個子區間,實際實驗時我們發現在億級別數據下,使用兩階段聚合,也會出現特定key 下的數據量特別大的情況,導致 Spark 頻繁GC,程序運行速度極其緩慢,甚至根本無法得到聚合後的結果。
為了解決這一問題,注意到通過劃分屬性進行劃分後,仍然會將特別大的group 按照一定大小進行切割,那麼直接在聚合過程中融合這一步驟不就可以了麼,這樣就能解決特定屬性 值下數據特別多的情形,也能極大地提升算法運行效率。
三階段自適應聚合分為以下四個階段:
- 隨機局部聚合:設定一個較大的數(如 100),參照兩階段聚合第一階段操作給每個 key 打上一個隨機數,對打上隨機數後的 key 進行聚合操作;
- 自適應局部聚合:經過隨機局部聚合後,可獲取每個隨機key 下的記錄條數,通過單個隨機key 下的記錄條數,我們可以對原key 下的數據條數進行估算,並自適應地 調整第二次局部聚合時每個原始key 使用的隨機數值;
- 第二輪隨機局部聚合;根據自適應計算得到的隨機數繼續給每個key 打上隨機數,注意此時不同key 使用的隨機數值可能是不同的,並對打上隨機數後的key 進行第二輪 局部聚合;
- 全局聚合:經過第二輪隨機局部聚合後,若特定key 下記錄數超過設定閾值(如5000),則保留該結果,不再進行該階段全局聚合;否則,則將隨機key 還原為原始key 值,進行最後一階段的全局聚合。
Faster, Faster, Faster
經過以上調優後,程序運行速度大致提升了 10 倍左右。 然而,在實驗中我們發現當對億級別用戶進行相似度計算並將邊按閾值過濾後,得到的邊數仍然在百億級別,佔用內存空間超過 2T。 那麼我們有沒有可能減小這一內存佔用呢? 答案是肯定的。
通過對整個異常用戶檢測流程進行細緻的分析,我們發現我們並不需要對子空間內所有用戶對進行相似度計算,通過前期實驗我們發現當用戶可疑度超過0.7 時,基本就可以判定該用戶是 惡意用戶。 根據用戶可疑度計算公式反推,當節點關聯邊的權重超過 18.2 時,其在最後結果中的權值就會超過 0.7,基於這一想法,我們引入了動態 Dropping 策略。
動態 Dropping 策略
引入HashMap 保存當前子空間每個節點的累計權重值,初始化為0.0;按照原始算法依次遍歷子空間下的節點對,若節點對兩個節點累計權重值均超過閾值(18.2),則跳過該 節點對權值計算,否則則根據原始算法計算節點對權重,並累加到HashMap 中,更新關聯節點的累積權重值。
引入動態Dropping 策略後,對於較大的用戶子空間,程序會跳過超過90% 的節點對的相似度計算,極大地減少了計算量;同時,億級別用戶相似度計算生成的邊的內存佔用 從原來超過2T 降到50G 左右,也極大地降低了程序所需內存佔用。
圖劃分策略
通過相似度計算得到的用戶相似度關係圖節點分佈是極不均勻的,大部分節點度數較小,少部分節點度數較大,對於這種分佈存在嚴重傾斜的網絡圖,圖劃分策略的選擇對 圖算法性能具有極大影響。 為了解決這一問題,我們使用 EuroSys 2015 Best Paper 提出的圖劃分算法 HybridCut 對用戶相似度關係圖進行劃分。
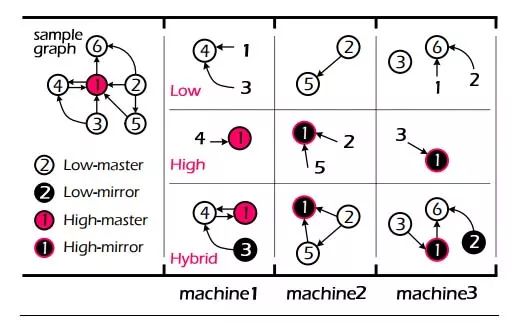
圖 4 HybridCut 圖劃分算法
如圖4 所示,HybridCut 圖劃分算法根據節點度數的不同選取差異化的處理策略,對於度數較低的節點,如節點2,3,4,5,6,為了保證局部性,算法會將其 集中放置在一起,而對於度數較高的節點,如1,為了充分利用圖計算框架並行計算的能力,算法會將其對應的邊攤放到各個機器上。
通過按節點度數對節點進行差異化的處理,HybridCut 算法在局部性和算法並行性上達到了較好的均衡。 以上僅對 HybridCut 算法基本思路進行粗略的介紹,更多算法細節請參閱論文 PowerLyra: Differentiated Graph Computation and Partitioning on Skewed Graphs。
總結和討論
優點與不足
優點
上述異常用戶檢測框架具有如下優點:
- 能夠較好地檢測惡意用戶可能存在的環境聚集和屬性聚集,且具有較高的準確率和覆蓋率;
- 能夠自然地融合畫像信息以及反垃圾信息,通過融合不同粒度的信息,可提高算法的覆蓋率,同時也給算法提供了更大的設計空間,可以按需選擇使用的特徵或信息;
- 良好的擴展性,可直接擴展到億級別用戶進行惡意用戶檢測,且算法具有較高的運行效率。
不足
- 無法對非環境和屬性聚集的惡意用戶進行檢測 (當然,這也不在方案的設計目標裡),無法處理惡意用戶使用外掛等手段繞過環境和屬性聚集檢測的情況;
- 上述方案權重策略部分需要人工指定權重,這無疑增加了人工調參的工作量,若黑產惡意模式或使用特徵發生較大的變更,則可能需要對權重重新進行調整,維護成本較高。
Next…
- 探索自動化的權重生成策略,以應對可能的特徵或黑產模式變更;
- 是否可以根據聚類過程中的信息生成規則,用於實時惡意打擊;
- 上述方案比較適合用來檢測惡意用戶可能存在的環境聚集和屬性聚集,對於非環境和屬性聚集的惡意類型則顯得無能為力了(一種可能的方案是將連續屬性離散化,不過這樣太不優雅了 !),因此後續我們會嘗試從行為維度對用戶行為進行分析,並構建相應的打擊模型。
參考文獻
- Chen R, Shi J, Chen Y, et al. PowerLyra: differentiated graph computation and partitioning on skewed graphs[C]// Tenth European Conference on Computer Systems. ACM, 2015:1.
- Spark 性能優化指南——高級篇 https://tech.meituan.com/spark-tuning-pro.html
作者:青原行思(微信安全)/李琦、元東、苗園莉(清華大學深圳研究生院)
來源:微信公眾號:騰訊大講堂(ID:TX_DJT)
題圖來自PEXELS,基於CC0協議