
摘要:剛剛,OpenAI提出一種實驗性元學習方法EvolvedPolicyGradients(EPG),該方法演化學習智能體的損失函數,從而實現在新任務上的快速訓練。 OpenAI
發布一種實驗性元學習方法E
剛剛,OpenAI 提出一種實驗性元學習方法 Evolved Policy Gradients(EPG),該方法演化學習智能體的損失函數,從而實現在新任務上的快速訓練。
OpenAI
發布一種實驗性元學習方法 Evolved Policy
Gradients(EPG),該方法從學習智能體的損失函數發展而來,可實現在新任務上的快速訓練。 測試時,使用 EPG
訓練的智能體可在超出訓練範疇的基礎任務上取得成功,比如學習從訓練時某物體的位置導航至測試時該物體的位置(房間另一側)。
EPG
訓練智能體,使其具備如何在新任務中取得進展的先驗知識。 EPG
沒有通過學得的策略網絡編碼先驗知識,而是將其編碼為學得的損失函數。 之後,智能體就能夠使用該損失函數(被定義為時序卷積神經網絡)快速學習新任務。 OpenAI
展示了 EPG 可泛化至超出分佈(out of
distribution)的測試任務,其表現與其他流行的元學習算法有質的不同。 在測試中,研究人員發現 EPG 訓練智能體的速度快於
PPO(一種現成的策略梯度方法)。 EPG 與之前為強化學習智能體設計適合的獎勵函數的研究(Genetic Programming for
Reward Function Search 等)有關,不過 EPG
將這個想法泛化至演化一個完整的損失函數,這意味著損失函數必須高效學習內部的強化學習算法。
第一個視頻展示了 OpenAI 的方法如何教會機器人在不重置環境的情況下到達不同的目標,第二個視頻是 PPO 方法。 左上的數字表示目前的學習更新次數。 注意該視頻展示了完整的實時學習過程。
EPG
背後的設計知覺來自於我們都很熟悉的理念:嘗試學習新技巧,經歷該過程中挫折和喜悅的交替。 假設你剛開始學習拉小提琴,即使沒有人指導,你也立刻可以感覺到要嘗試什麼。 聽自己彈奏出的聲音,你就能感覺到是否有進步,因為你具備完善的內部獎勵函數,該函數來源於其他運動任務的先驗經驗,並且通過生物進化的過程演化而來。 相反,大部分強化學習智能體在接觸新任務時未使用先驗知識,而是完全依賴於外部獎勵信號來指導初始行為。 從空白狀態開始,也就難怪當前的強化學習智能體在學習簡單技巧方面比人類要差得遠了。 EPG
通過過去在類似任務上的經驗,朝「不是空白狀態、知道怎麼做才能完成新任務」的智能體邁出了一步。
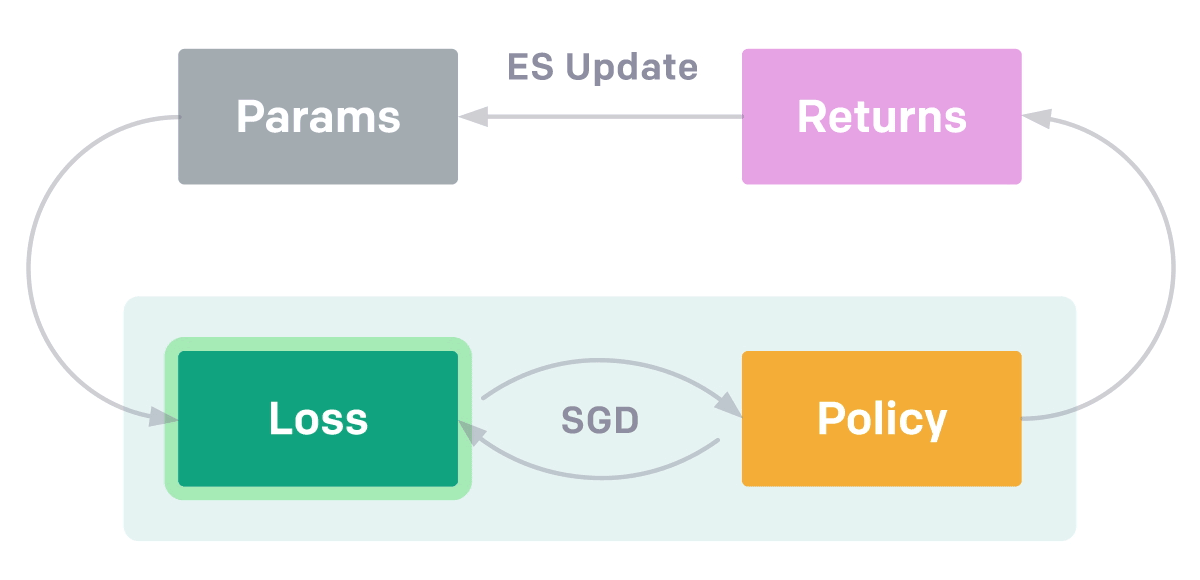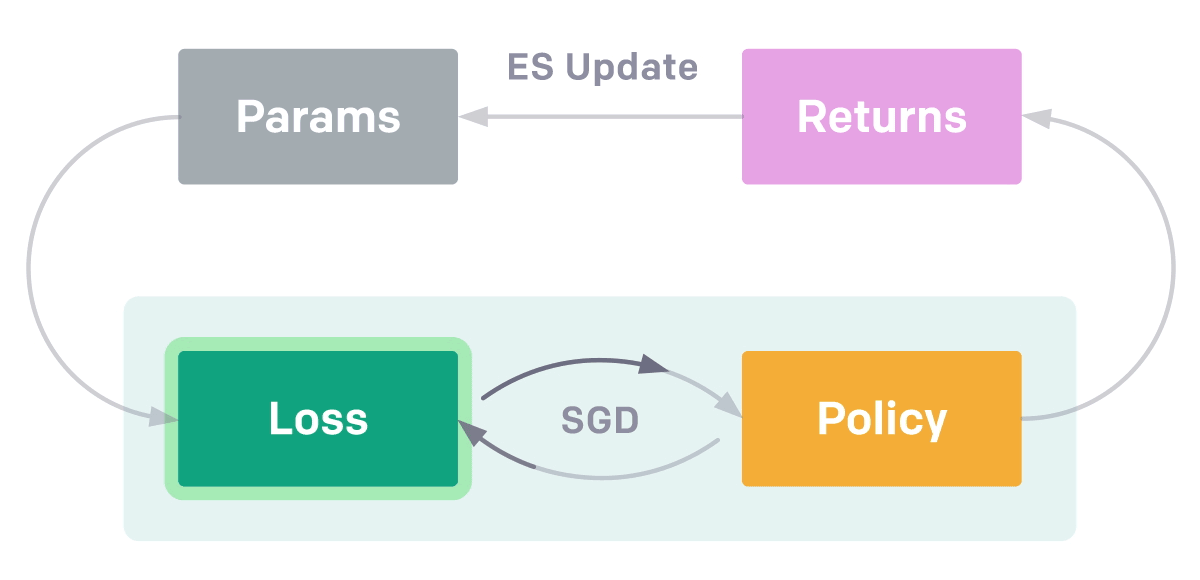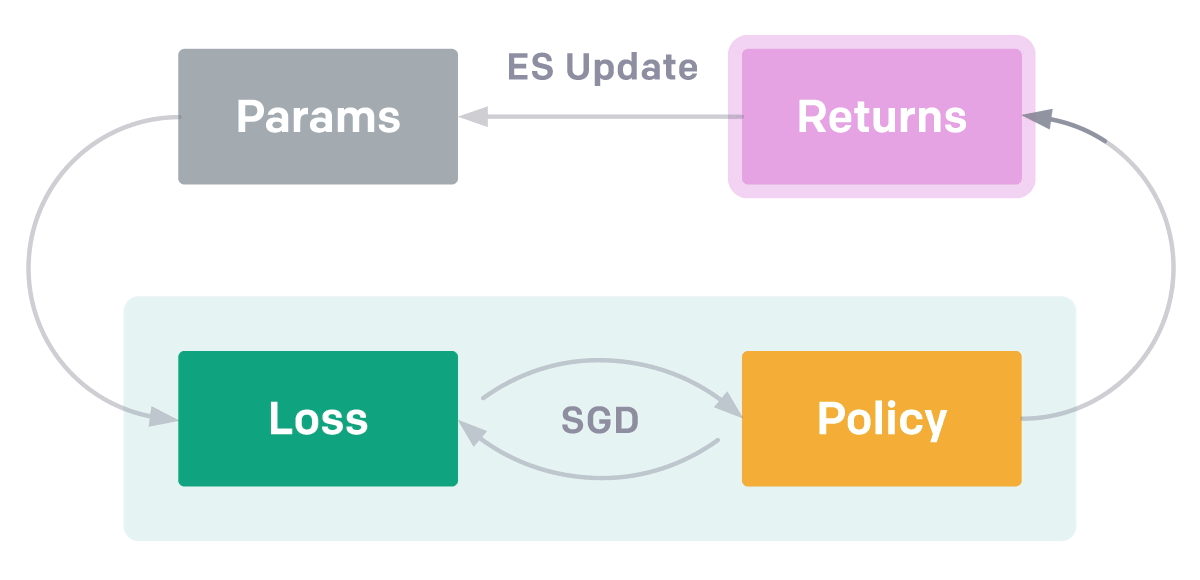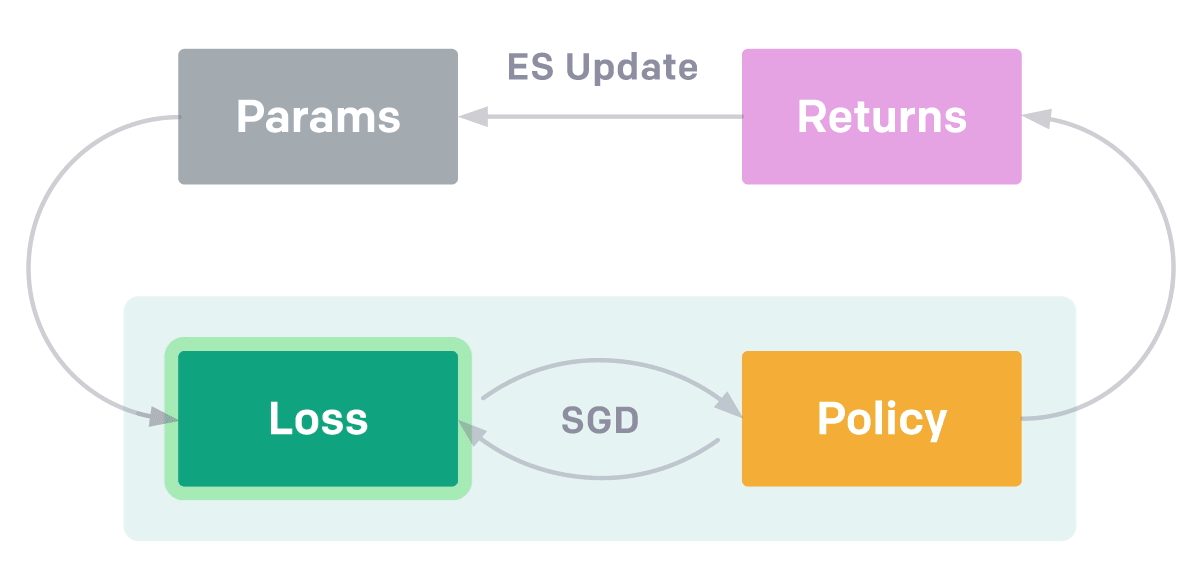
EPG
包含兩個優化循環。 在內部循環中,智能體從頭學習解決從一類任務中採樣的特定任務。 這類任務可能是「移動抓器到某個位置 [x,
y]」。 內部循環使用隨機梯度下降(SGD)來優化智能體策略,對抗外部循環中的損失函數。 外部循環評估內部循環學習所得的返回結果,並使用進化策略(ES)調整損失函數的參數,以提出可帶來更高返回結果的新型損失函數。
具備學得的損失函數比當前的強化學習方法有多個優勢:使用進化策略來演化損失函數允許我們優化真正的目標(最終訓練出的策略性能)而不是短期返回結果,EPG 通過調整損失函數適應 環境和智能體歷史,從而優於標準的強化學習算法。


上圖展示了 OpenAI 的方法如何教會機器人反向跳躍,下面的圖是 PPO 方法。 EPG 帶來了智能體的探索行為,智能體在意識到反向行走會帶來高獎勵之前已經嘗試反向行走了。 左上的數字表示目前的學習更新次數。 注意該視頻展示了完整的實時學習過程。
近期出現了大量關於元學習策略的研究,我們必須要問為什麼學習損失函數,而不是直接學習策略? 學習循環策略可能會使當前任務出現過擬合,而學習策略初始化會在探索時限製表達性。 OpenAI
的動機是期望損失函數可以很好地泛化至大量不同任務中。 這當然適用於手工調整的損失函數:設計完備的強化學習損失函數(如 PPO
中的損失函數)可以廣泛應用於大量任務(從 Atari 遊戲到控制機器人)。
為了測試 EPG
的泛化能力,研究者設置了一個簡單的實驗,演化 EPG
損失直到智能體「螞蟻」有效地移動到圓形運動場右側的隨機目標位置。 然後,固定損失函數,給螞蟻一個新的目標,這一次是左側的位置。 令人驚訝的是,螞蟻學會了走到左側! 以下是它們的學習曲線展示(紅線):

結果非常好,因為它展示了在「超出訓練分佈」的任務中的泛化效果。 這種泛化很難達到。 OpenAI
研究人員將 EPG 與另一種元學習算法 RL2 進行了對比,後者嘗試直接學習可用於新型任務的策略。 實驗表明,RL2
確實可以成功地讓智能體走向屏幕右側的目標。 但是,如果測試時的目標是在屏幕左側,則智能體失敗,還是一直向右走。 也就是說,其對訓練任務設置(即向右走)產生「過擬合」。

上述視頻(見原文)展示了 OpenAI 的方法(左)如何從頭開始教會機器人行走和到達目標(綠色圈),右側是 RL2。 左上的數字表示目前的學習更新次數。 注意該視頻展示了 3X 實時速度時的完整學習過程。
和所有的元學習方法一樣,該方法仍然存在許多限制。 現在,我們可以訓練一次性處理一類任務的
EPG 損失函數,例如,讓一隻螞蟻左右走。 然而,面向這類任務的 EPG
損失函數對其他不同類任務未必有效,例如玩《太空侵略者》遊戲。 相比之下,標準的 RL
損失具備這種泛化能力,同一損失函數可被用於學習大量不同的技能。 EPG
獲得了更好的表現,卻失去了泛化能力。 要想同時得到性能與泛化能力,元學習方法還有很長的路要走。
版權聲明
本文僅代表作者觀點,不代表百度立場。
本文係作者授權百度百家發表,未經許可,不得轉載。