
摘要:作為搜索引擎起家的科技巨頭,谷歌曾推出過很多有意思的搜索工具。 昨天,這家公司的研究機構發布了一款基於人工智能的搜索引擎,該實驗項目可以讓普通人也能感受最新語義理解和自然語言處理技術的強大能力:它們是目
作為搜索引擎起家的科技巨頭,谷歌曾推出過很多有意思的搜索工具。 昨天,這家公司的研究機構發布了一款基於人工智能的搜索引擎,該實驗項目可以讓普通人也能感受最新語義理解和自然語言處理技術的強大能力:它們是目前人工智能技術發展的重要 方向。 值得一提的是,《奇點臨近》一書的作者,谷歌研究院工程總監雷·庫茲韋爾也參與了這一工作
這一項目目前包含交互式 AI 語言工具,它展示的主要人工智能技術是「詞向量」。 詞向量是一種自然語言處理形式,向量的一些幾何性質能夠很好的反映詞的句法或者句義。 例如,兩個詞向量的差值對應詞的關係,詞向量的距離則對應詞的相關或者相似性。 對於選定的一組詞,將其向量投影到空間中,詞義相近的詞向量在向量空間中表現出了有趣的聚類現象。 例如國家名詞聚成一類,大學名稱則形成另一個聚類。
自然語言理解在過去幾年發展迅速,部分要歸功於詞向量的發展,詞向量使算法能夠根據實際語言的使用實例了解詞與詞之間的關係。 這些向量模型基於概念和語言的對等性、相似性或關聯性將語義相似的詞組映射到鄰近點。 去年,谷歌使用語言的層次向量模型對 Gmail 的 Smart Reply 進行了改進。 最近,谷歌一直在探索這些方法的其他應用。
今天,谷歌向公眾分享了 Semantic Experiences 網站,該網站上有兩個示例,展示了這些新的方法如何驅動之前不可能的應用。 Talk to Books 是一種探索書籍的全新方式,它從句子層面入手,而不是作者或主題層面。 Semantris 是一個由機器學習提供支持的單詞聯想遊戲,你可以在其中鍵入與給定提示相關聯的詞彙。 此外,谷歌還發布了論文《Universal Sentence Encoder》,詳細地介紹了這些示例所使用的模型。 最後,谷歌為社區提供了一個預訓練語義 TensorFlow 模塊,社區可以使用自己的句子或詞組編碼進行實驗。
建模方法
谷歌提出的方法通過為較大的語言塊(如完整句子和小段落)創建向量,擴展了在向量空間中表徵語言的想法。 語言是由概念的層次結構組成的,因此谷歌使用模塊的層次結構來創建向量,每個模塊都要考慮與不同時間尺度上的序列所對應的特徵。 關聯、同義、反義、部分關係、整體關係以及許多其他類型的關係都可以用向量空間語言模型來表示,只要我們以正確的方式進行訓練,並且提出正確的「問題」。 谷歌在論文《Efficient Natural Language Response for Smart Reply》中介紹了這種方法。
Talk to Books
通過 Talk to Books,谷歌提供了一種全新的圖書搜索方式。 你陳述一件事或提出一個問題,這個工具就會在書中找出能回答你的句子,這種方法不依賴關鍵詞匹配。 從某種意義上來說,你在和書「交談」,得到的回答可以幫助你確定自己是否有興趣閱讀它們。

Talk to Books
該模型在十億聊天句對上訓練而成,學習識別哪些可能是好的回复。 一旦你問問題(或者作出陳述),工具就在搜索十萬本書中的所有句子,根據句子層面的語義找到與輸入語句對應的內容;沒有限制輸入和輸出結果之間關係的預置規則。
這是一種獨特的能力,可以幫助你找到關鍵詞搜索未必找得到的有趣書籍,但是仍有改進空間。 例如,上述實驗在句子層面有作用(而不是像 Gmail 的 Smart Reply 那樣是在段落層面),那麼「完美」匹配的句子可能仍屬「斷章取義」。 你可能會發現找到的書或文章並非自己想要的,或者選中某篇文章的理由並不明顯。 你還可能注意到著名的書籍未必排序靠前;該實驗僅觀察了單個句子的匹配程度。 不過,它有一個好處,就是這個工具可以幫助人們發現意想不到的作者和書籍,以及 surface book。
Semantris
谷歌還發布了 Semantris,一個由該技術支持的單詞聯想遊戲。 你輸入一個單詞或詞組,遊戲屏幕上會排列出所有單詞,排序根據這些單詞與輸入內容的對應程度。 使用該語義模型,近義詞、反義詞和鄰近概念都不在話下。
試用地址:https://research.google.com/semantris
Arcade 版本(見下圖)的時間壓力使得你輸入單個單詞作為提示。 而 Blocks 版本沒有時間壓力,你可以盡情嘗試輸入詞組和句子。
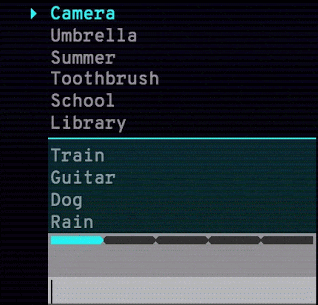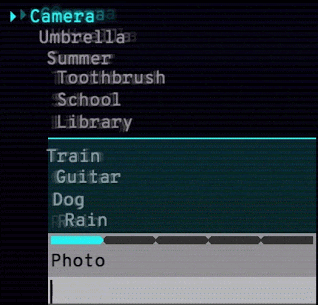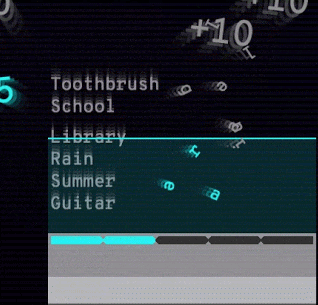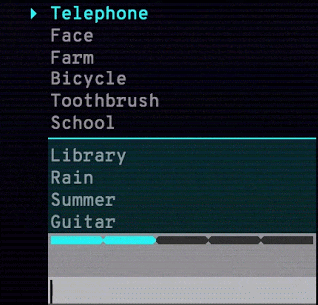
Semantris Arcade
本文分享的示例僅僅是使用這些新工具的幾個可能方式。 其他潛在應用還包括分類、語義相似度、語義聚類、白名單應用(從多個方案中選擇正確的回复)和語義搜索(比如 Talk to Books)。 期待社區提出更多想法和更多有創意的應用案例。
相關論文:Universal Sentence Encoder

論文鏈接:https://arxiv.org/abs/1803.11175
摘要: 我們展示了將句子編碼成嵌入向量的模型,可用於面向其他 NLP 任務的遷移學習。 該模型高效,且在多項遷移任務中性能良好。 該編碼模型的兩個變體允許準確率和計算資源之間的權衡。 對於這兩種變體,我們調查並作了關於模型複雜度、計算資源消耗、遷移任務可用性和任務性能之間關係的報告。 我們將該模型與通過預置詞嵌入使用單詞級別遷移學習的基線模型和未使用遷移學習的基線模型進行了對比,發現使用句子嵌入的遷移學習性能優於單詞級別的遷移學習。 句子嵌入的遷移學習在具備少量監督訓練數據的遷移任務中也能實現非常好的性能。 我們在檢測模型偏差的詞嵌入關聯測試(WEAT)中獲得了很好的結果。
版權聲明
本文僅代表作者觀點,不代表百度立場。
本文係作者授權百度百家發表,未經許可,不得轉載。