
計算用戶/物品相似度,以相似度作為權重,對不同物品進行評分預測,從而實現物品。

什麼是協同過濾
先舉個生活中的場景,你想听歌卻不知道聽什麼的時候,會向你身邊與你品位類似的朋友求助,從而獲得他的推薦。 協同過濾(Collaborative Filtering,簡稱CF)就像與你品味相近的朋友,通過對大量結構化數據進行計算,找出與你相似的其他用戶(user)或與你喜歡的物品(item)相似的物品 ,從而實現物品推薦。
協同過濾分為兩類:基於用戶的協同過濾(User-Based CF)和基於物品的協同過濾(Item-Based CF)。 結合前文的介紹便不難理解分別的應用場景。
計算相似度之前需要先準備一些如下表所示的數據集:
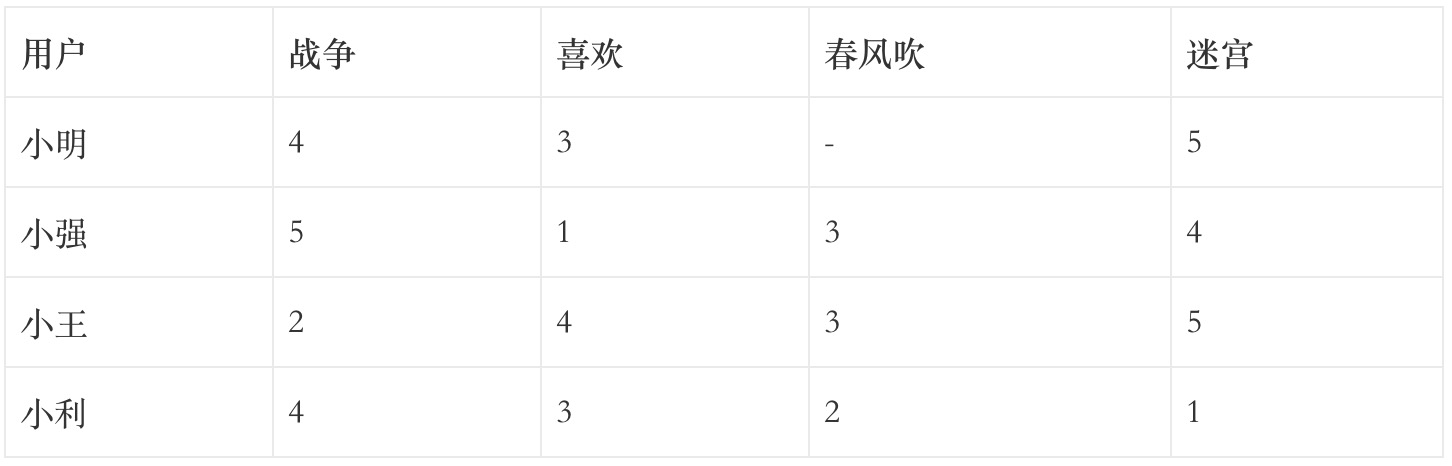
它是一種表達不同人對不同物品偏好的方式,例如音樂應用可以用0和1表示喜歡不喜歡和喜歡。
User-Based CF
如果你和小明對於音樂的品位相似,假如小明喜歡聽Adele,那麼你也有可能喜歡聽。 好了,問題來了:
- 如何衡量兩個用戶是否相似?
- 如何根據相似用戶推薦物品?
相似度計算
相似度通過如下公式計算得到:
y = f(data, user1, user2)
其中,data就是前文提到的數據集,user1和user2表示要比較的兩個用戶或物品。 書中主要介紹了兩種相似度計算函數:歐幾里得距離評價、皮爾遜相關度評價。
(1)歐幾里得距離
它以經過人們一致評價的物品為坐標軸,然後將參與評價的人繪製到圖上,並考察他們彼此間的距離遠近。 輸出滿足y∈[0,1],1表示user1和user2具有相同的偏好,0表示user1和user2偏好不同。
(2)皮爾遜相關度
它是比歐幾里得距離更複雜的一種表示相似度的方法。 用於判斷兩組數據與某一直線擬合程度,在數據不是很規範的時候(比如,影評者對影片的評價總是相對於平均水平偏離很大時),會傾向於給出更好的 結果。 皮爾遜可以簡單理解為cos(x)函數,所以其輸出滿足y∈[-1,1],1表示user1和user2具有相同的偏好,0表示user1和user2偏好不同,-1表示user1和user2偏好 負相關。 如果難以理解可以參考: 如何理解皮爾遜相關係數(Pearson Correlation Coefficient)?
由於本人高數上下都是勉強及格,對於這兩個函數理解的也不深,所以沒辦法深入淺出的解釋,不過只要知道每種計算方法的適應範圍和局限性就好了。
推薦物品
第一個問題解決了,來看看如何推薦物品。 如果只是把相似用戶喜歡的物品推薦給被推薦者,未免過於草率,而且又該如何選擇相似用戶呢。
(1)推薦算法
結合前文數據集進行說明:
- 計算出所有用戶兩兩之間的相似度;
- 指定一個被推薦者:小明;
- 找出其他用戶評價過且被推薦者未評價的物品:春風吹;
- 以被推薦者與他人的相似度作為權,將權與其他用戶對該物品的評分相乘;
- 【x春風吹】一列值之和除以相似度一列值之和,最終結果(2.875)便為預測的小明對於春風吹的評分。
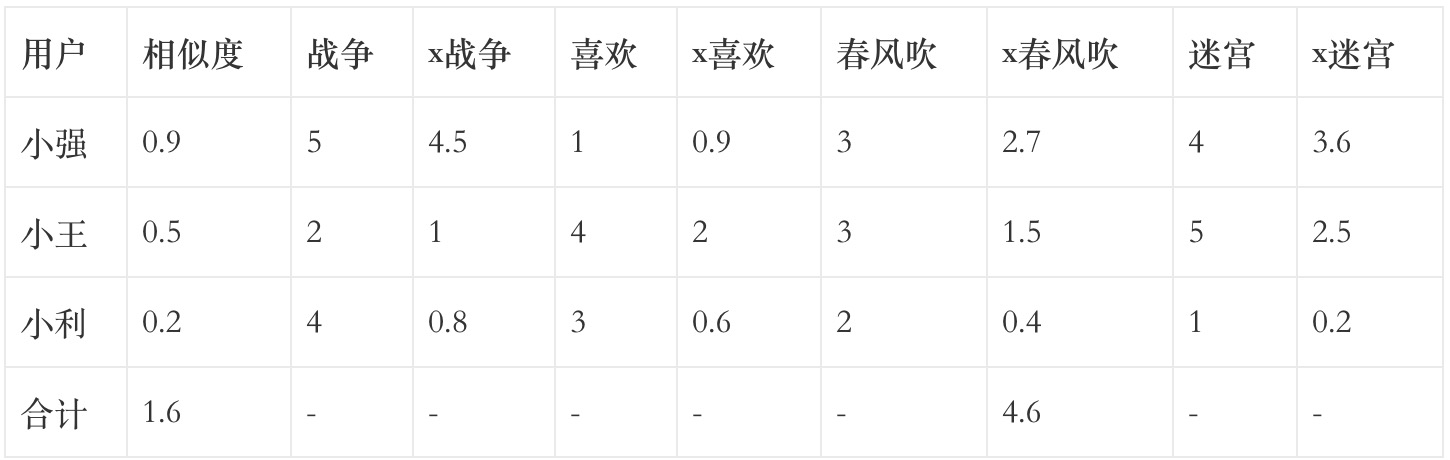
注:相似度隨便寫的,並非計算所得。
至此可以給出推薦算法公式:
y = f(data, user, sim)
其中,data就是前文提到的數據集,user為被推薦者,sim為相似度計算函數,可以根據場景不同選擇不同的計算函數。 從輸出總選擇評分較高的物品推薦給用戶,從而實現物品推薦。
Item-Based CF
基於物品的推薦思路是:根據你評價過的物品,找出與其相似的物品。
相似度計算
方法與User CF相同,只是我們需要把前文數據集進行轉置,併計算所有物品兩兩之間的相似度。
推薦物品
如同User CF,我們不能簡單的推薦與我們偏好物品類似的物品。
(1)推薦算法
- 計算出所有物品兩兩之間的相似度;
- 指定一個被推薦者;
- 找出被推薦者評價過的物品;
- 以被推薦者評價過的物品與其他物品的相似度作為權,將權與被推薦者對該物品的評分相乘;
- 【xXX】一列值之和除以相似度一列值之和,最終結果便為預測的被推薦者對於其未評價過物品的評分。
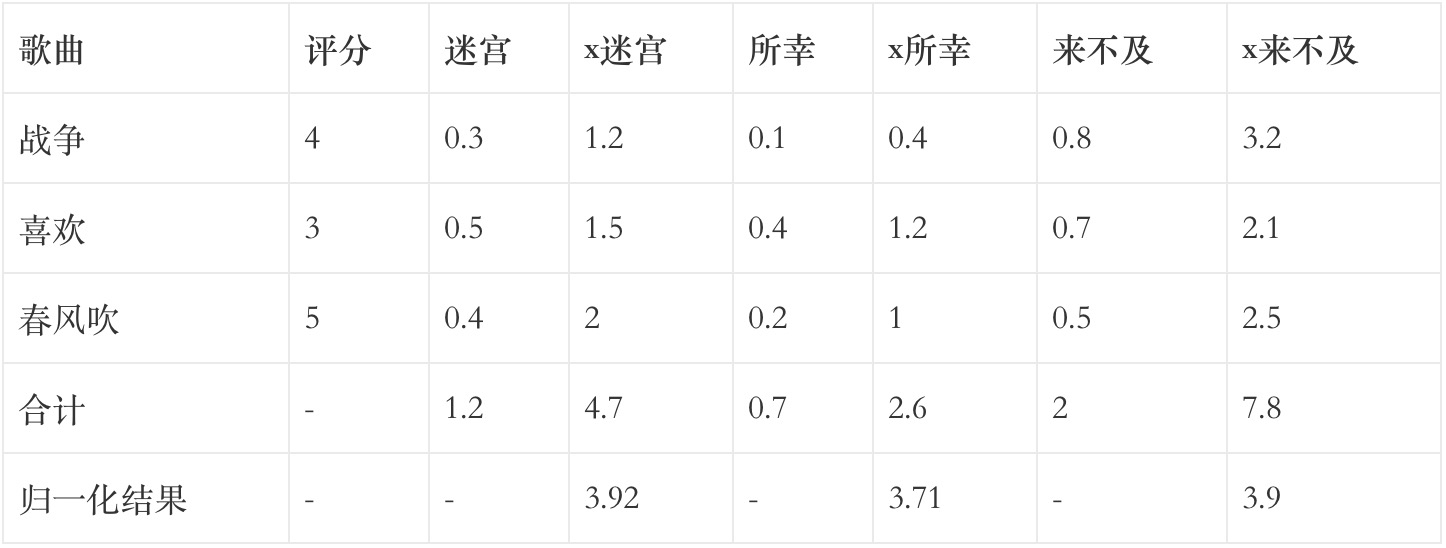
注:相似度隨便寫的,並非計算所得;並且根據說明需要增加了一些音樂。
至此可以給出推薦算法公式:
y = f(data, itemMatch, user)
其中,data就是前文提到的數據集,user為被推薦者,itemMatch為所有物品兩兩之間相似度的數據集,計算itemMatch時,可以根據場景不同選擇不同的計算函數。 從輸出總選擇評分較高的物品推薦給用戶,從而實現基於物品的物品推薦。
如何選擇?
1. 基於物品進行過濾的方式要過於基於用戶的方式,不過它需要維護物品相似度表的額外開銷,這也是它快的原因;
2. 對於稀疏數據集,Item-Based CF效果優於User-Based CF;
3. 對於密集數據集,兩者效果幾乎相同;
4. 最重要的是,結合應用場景選擇合適的方法。
一句話心得
我對於協同過濾的理解是:
計算用戶/物品相似度,以相似度作為權重,對不同物品進行評分預測,從而實現物品。
本文由 @會編程的狗 原創發佈於人人都是產品經理。 未經許可,禁止轉載。
題圖來自 Unsplash,基於 CC0 協議